*只能從 Node 下手嗎?也不一定啦.... (´・Д・)」
前篇介紹了利用標籤(label)為 Pod 和 Node 做對應,以此去限制或調整部署的偏好。
其實,不只是 Node,也可以基於 Node 中運行的 Pod 做判斷喔!
與 nodeAffinity 些微不同,podAffinity 也兩種設定類型可以使用:
requiredDuringSchedulingIgnoredDuringExecution
preferredDuringSchedulingIgnoredDuringExecutionpodAffinity 不支援 requiredDuringSchedulingRequiredDuringExecution
apiVersion: v1
kind: Pod
metadata:
name: myapp
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- backend
topologyKey: "kubernetes.io/hostname"
containers:
- name: nginx-container
iamge: nginx
看起來跟 nodeAffinity 差不多啊
格式和邏輯基本上是一樣的。
適用於 Pod 有相依性的場景使用,部署在同一個節點上可以降低延遲,提升運行效率。
比如說: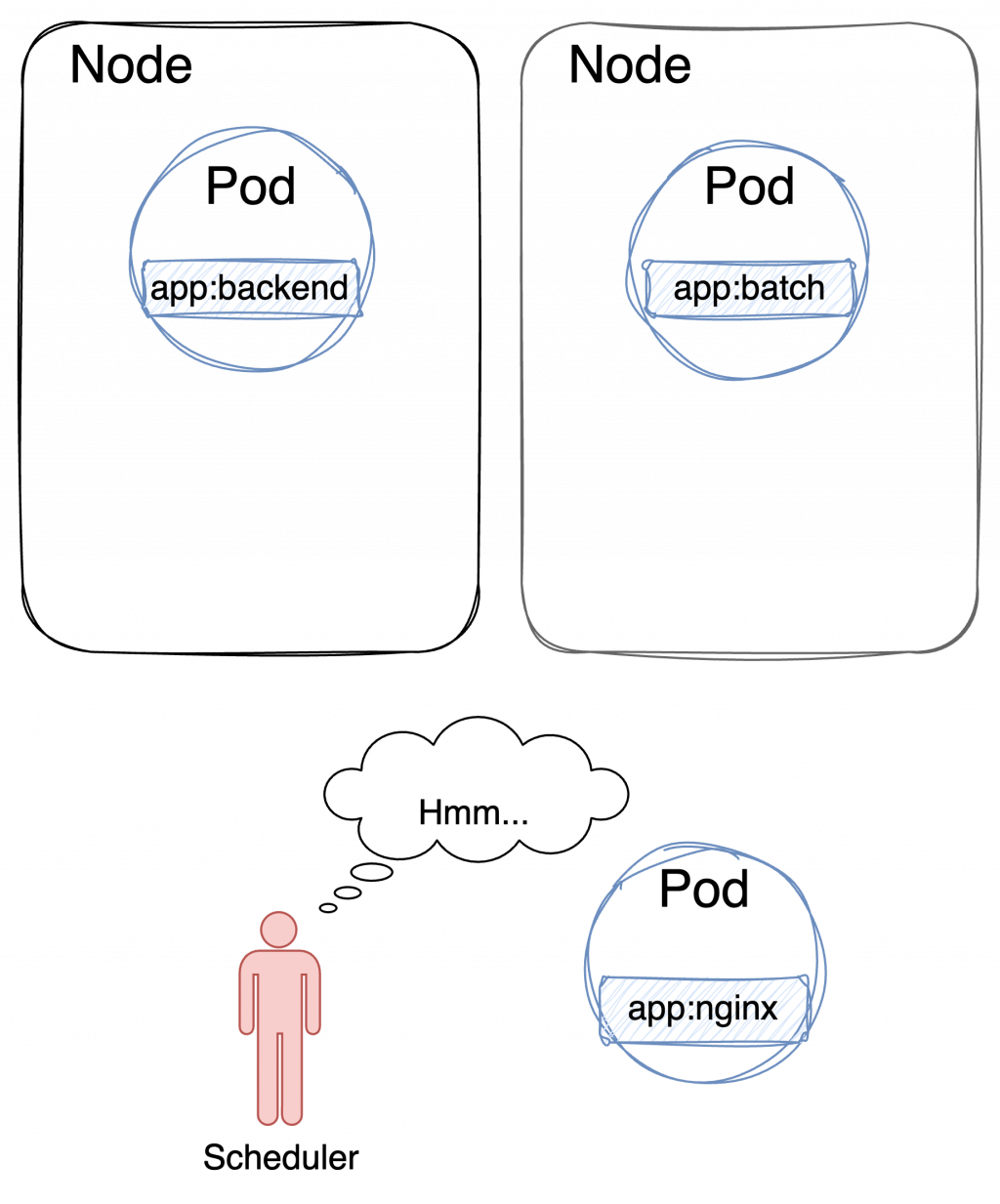
Pod 的 設定如下:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- backend
topologyKey: "kubernetes.io/hostname"
Pod 必須 與包含標籤:app:backend 的 Pod 運行在同一個 Node 上。
所以當然就...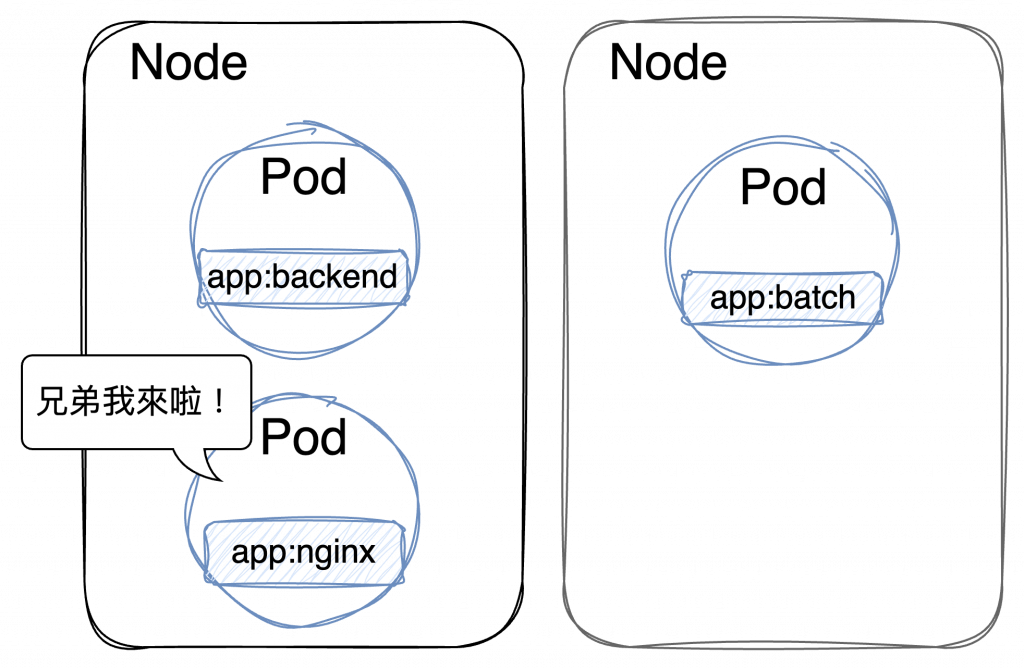
這時候就出現了一個疑問,如果我有很多選擇呢?
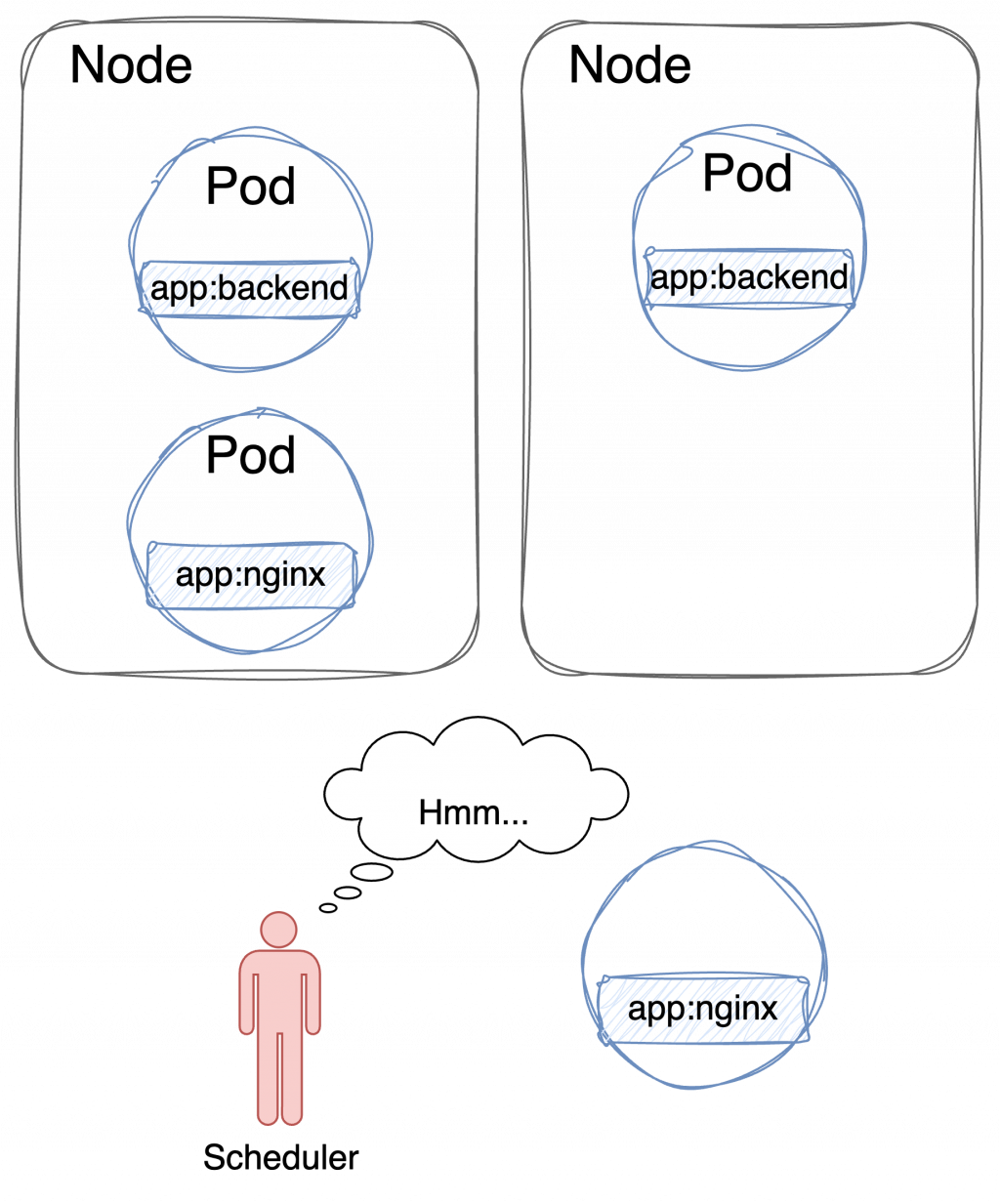
部署的結果會是: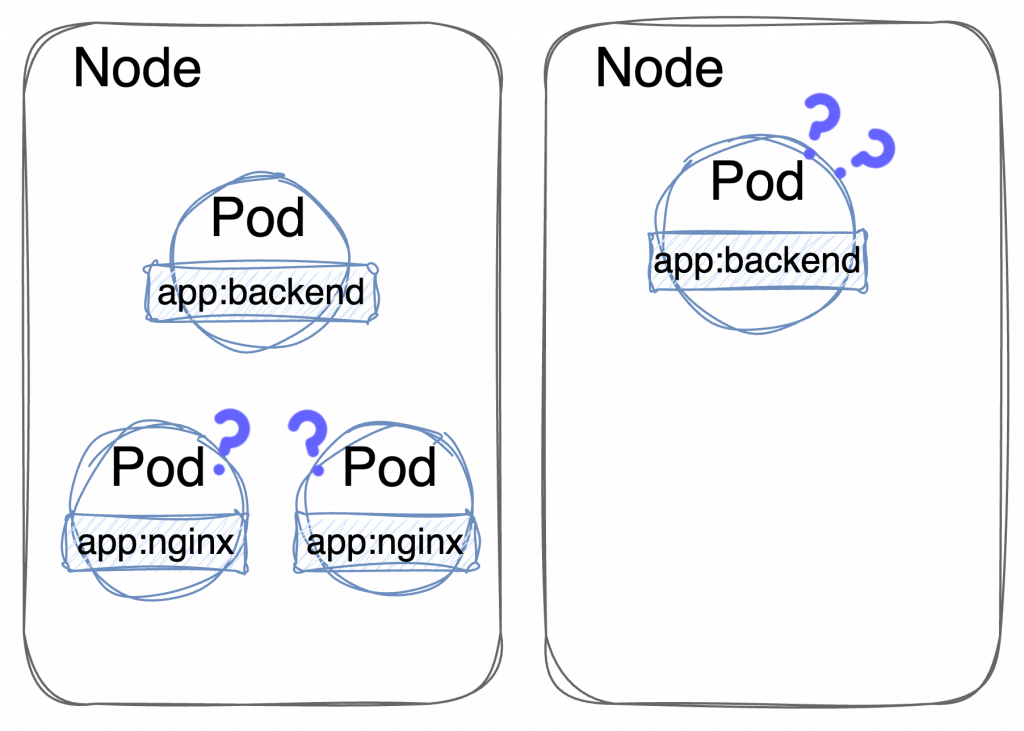
還是:
雖說單純照圖中的判斷,Kubernetes 可能會判斷右邊的 Node 比較資源比較充裕,所以把待部署的 nginx Pod 綁定上去,但實際上運行的場景複雜得多,誰知道一定會怎麼樣。
如果 Affinity 沒設定好,難保不會發生這種情況...
也不說不行... 但萬一有個 Node 壞掉,上面的整套系統也就跟著掛了。
比較理想的情況應該是這樣:
為了達到將平均分散在 Cluster 中的效果,需增加兩個部署條件:
設定方式:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- system-1
- key: tier
operator: In
values:
- backend
topologyKey: "kubernetes.io/hostname"
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- system-1
- key: app
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"
podAffinity:與包含 app:system-1 及 tier:backend 的 Pod 運行在同一個 Node 上
podAntiAffinity:避開已經運行 app:system-1 及 tier:nginx Pod 的 Node
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- system-1
- key: tier
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- system-1
- key: app
operator: In
values:
- backend
topologyKey: "kubernetes.io/hostname"
以此類推做設定,就可以確保 backend 和 frontend 在同一個 Node 上,又不會相同系統全都擠在一起了!
概念是這樣啦...
理想很美好但現實很骨感。
官方文件有特別提醒:
podAffinity 和 podAntiAffinity 邏輯需要大量的處理,若 Cluster 中運行的 Pod 數量很多,會明顯減慢 Kubernetes 的調度效率,如果 Cluster 中運行著逾百個 Node,請不要使用這個調度設定。
podAffinity可用的設定邏輯:
podAffinity 不支援 Gt(大於)和 Lt(小於),這兩個邏輯只能在 nodeAffinity 使用。
hostname,另外還有 zone、region。hostname < zone < region。1~100,數字越大權重越高。目前提到的調度策略,包含 Taints & Tolerations、nodeAffinity、podAffinity 都是可以同時使用的。它們是三種不同的調度機制,每一種機制用來解決不同的需求。這三者可以互相協作來提供更靈活的調度策略,不過也須留意別讓配置過於複雜,導致難以維護跟偵錯。


 iThome鐵人賽
iThome鐵人賽